

SSR-NET
[链接] 2020 高光谱&多光谱
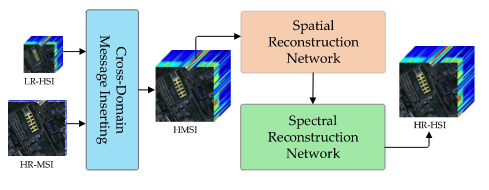
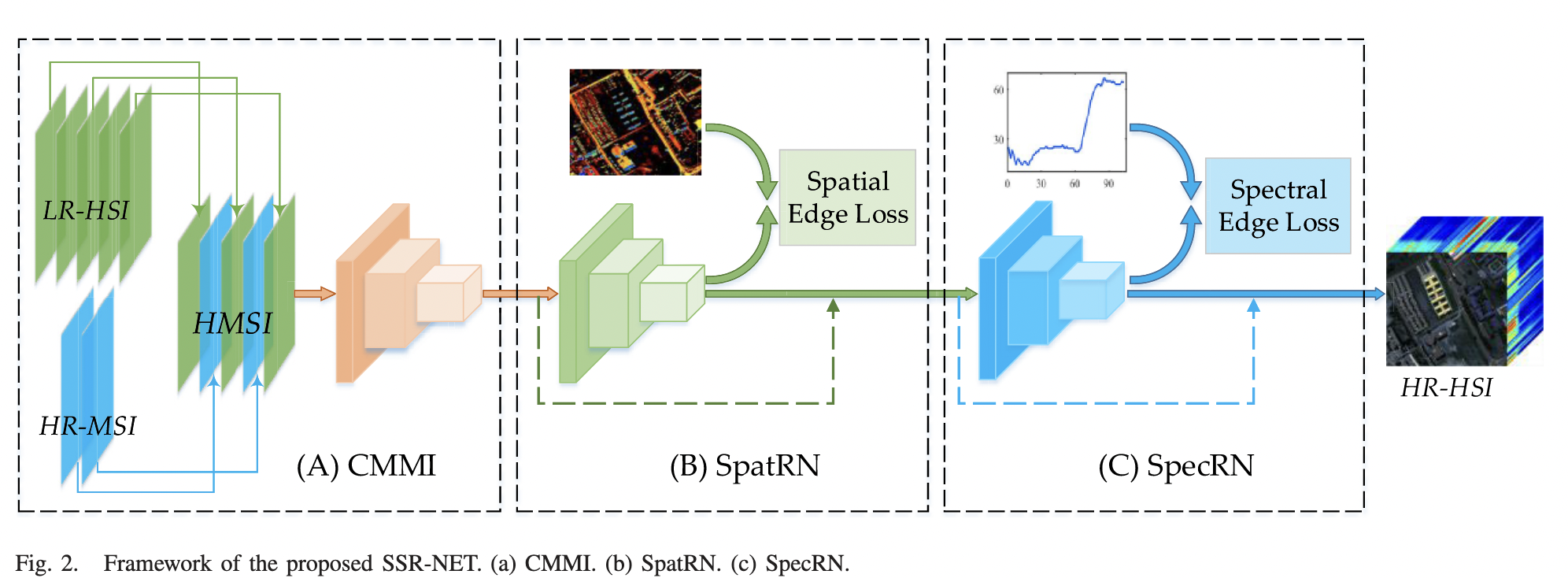
主要分为三个部分:
- Cross-Mode Message Inserting
CMMI的主要目的是产生一个超多光谱的图像,融合公式如下,Y(HR-MSI),X(LR-HSI)。
$Z_{pre}(k)=\left\{ \begin{aligned} Y(k)&,~if ~ k \in \{s_1,\dots,s_l\} \\ X(k)&\uparrow,~otherwise\end{aligned} \right.$
然后再通过一个卷积块
$Z_{pre}=ReLU(Conv_{pre}(Z_pre))$
- Spatial Reconstruction Network
$Z_{spat}=Z_{pre} + Conv_{spat}(Z_{pre})$
这里为了让SpatRN更关注空间信息,作者提出了spatial edge loss。该loss实际上是对图像在x方向和y方向的一阶导进行监督。(可能是GDL Loss的变形)
- Spectral Reconstruction Network
$Z_{spec} = Z_{spat} + Conv_{spec}(Z_{spec})$
同样,为了让模型关注谱的恢复,作者提出了spectral edge loss。该loss实际上是对图像在谱方向对的一阶导进行监督。
 |
 |
|---|---|
 |
最后模型的损失由三部分组成,spatial edge loss,spectral edge loss和fusion loss。
HAM-MFN
[链接] 2020 高光谱&多光谱
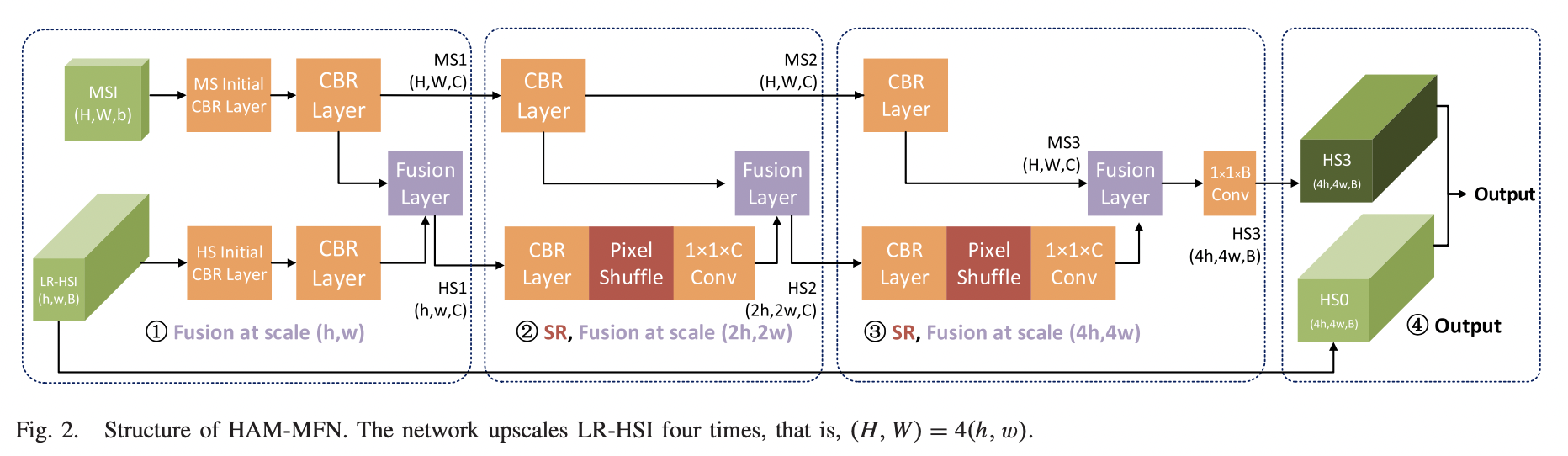
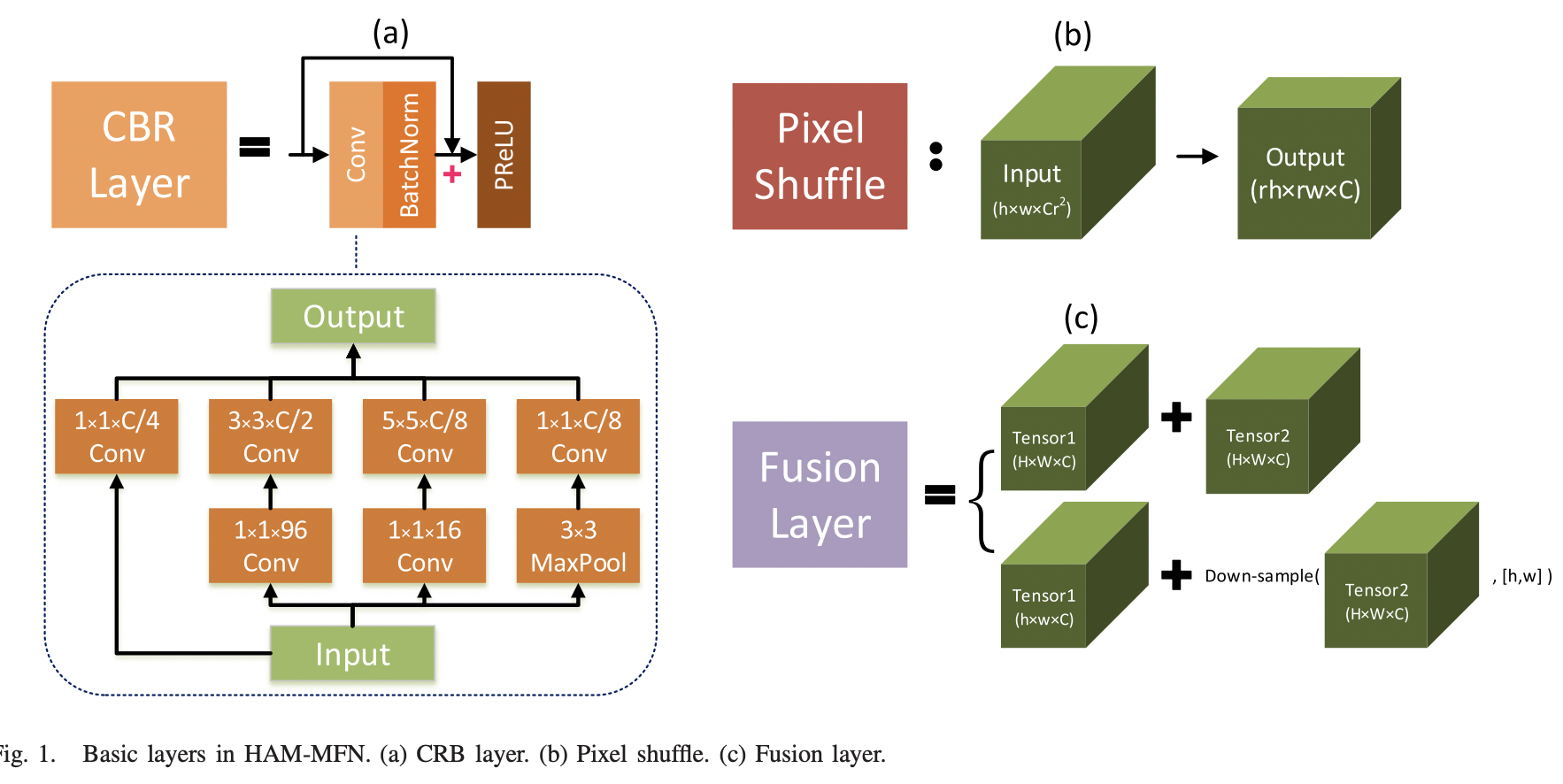
HAM-MFN网络主要由三个核心模块组成,CBR layer,Pixel Shuffle和Fusion Layer。
其中CBR Layer是借鉴了Inception的结构,并增加了残差连接用以增强特征提取。
Pixel Shuffle则是一种上采样操作,通过将输入$A \in R^{H\times W \times Cr^2}$进行reshape操作,得到新的特征图$B \in R^{rH \times rW \times C}$。其中r作为上采样因子超参,是可以人为进行调节的。
Fusion Layer则是将两个分支的特征图进行融合时采用的操作。
在示意图中,作者是对输入的HSI图像的尺寸(h,w)和MSI图像的尺寸(H,W)进行了假设,(H,W)=4(h,w)。
并且作者还提出了一种loss的计算方法RAP(RMSE+angle loss+Lap)
$L = RMSE + \lambda_1L_{angle}+\lambda_2L_{Lap}$
 |
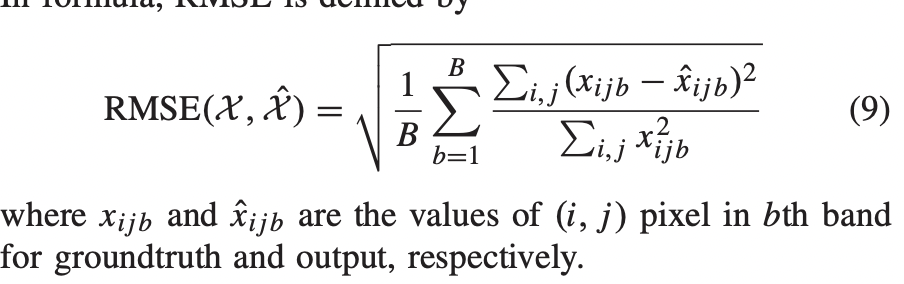 |
|---|---|
 |
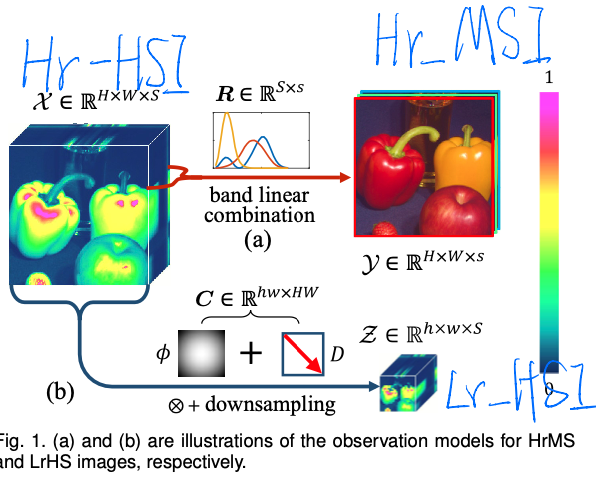
MHF-Net
[链接] 2020 高光谱&多光谱
作者首先引入了一组定理建立多光谱图像与GT的关系:
 |
 |
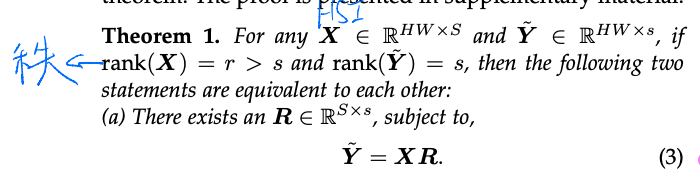
|
(1)对于高分辨率高光谱的图像(Ground Truth)$X$ 和高分辨率的多光谱图像$\tilde{Y}$之间存在如下关系:
$\tilde{Y} = XR$
(2)这一步不是很能理解,如果使用$\tilde{Y}$表示$X$的话,则需要引入一个残差量$\hat{Y}$:
$X = \tilde{Y}A + \hat{Y}B$
(3)而理论上的高分辨率的多光谱图像$\tilde{Y}$与实际的样本$Y$是存在差异的,这些差异是图像采集过程中的噪声$N_y$带来的:
$\tilde{Y} = Y - N_y$
最终对$X$进行表示:
$X=YA+\hat{Y}B+N_x,~N_x=-N_yA$

然后作者又引入一组定理将高光谱图像引入上述关系中来,建立一个GT和LR-HSI、HR-MSI之间的关系:
(4)对于高分辨率高光谱的图像(Ground Truth)$X$ 和低分辨率的高光谱图像$\tilde{Z}$之间存在如下关系:
$\tilde{Z} = CX$
(5)基于上述第(2)步:
$\tilde{Z}=C(\tilde{Y}A+\hat{Y}B)$
(6)在引入噪声量,实际训练样本$Z$:
$Z=C(YA+\hat{Y}B)+N,~ N=N_z-CN_yA$
这样就以重建HR-HSI为渠道,建立了LR-HSI样本$Z$和HR-MSI样本$Y$之间的关系。

最终作者设计了式(9)这样的一个损失,其中$f()$为正则项,并不使用先验知识来设计,而是通过网络学习得到。
式(9)中仅仅$\hat{Y}$为变量,因此作者设计了一个迭代式(10)用于优化$\hat{Y}$。
从(10)~(13)并不是很懂,但是作者最终得到一个迭代优化的式子(13)(14)。
将(14)式展开成如下几个操作,并通过DL模型进行表达
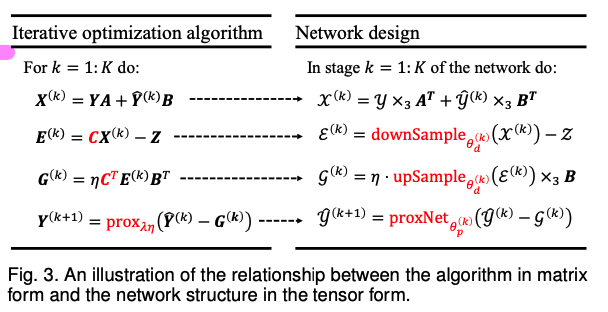
最后在模型的设计上,遵循上述的设计,如下图所示:
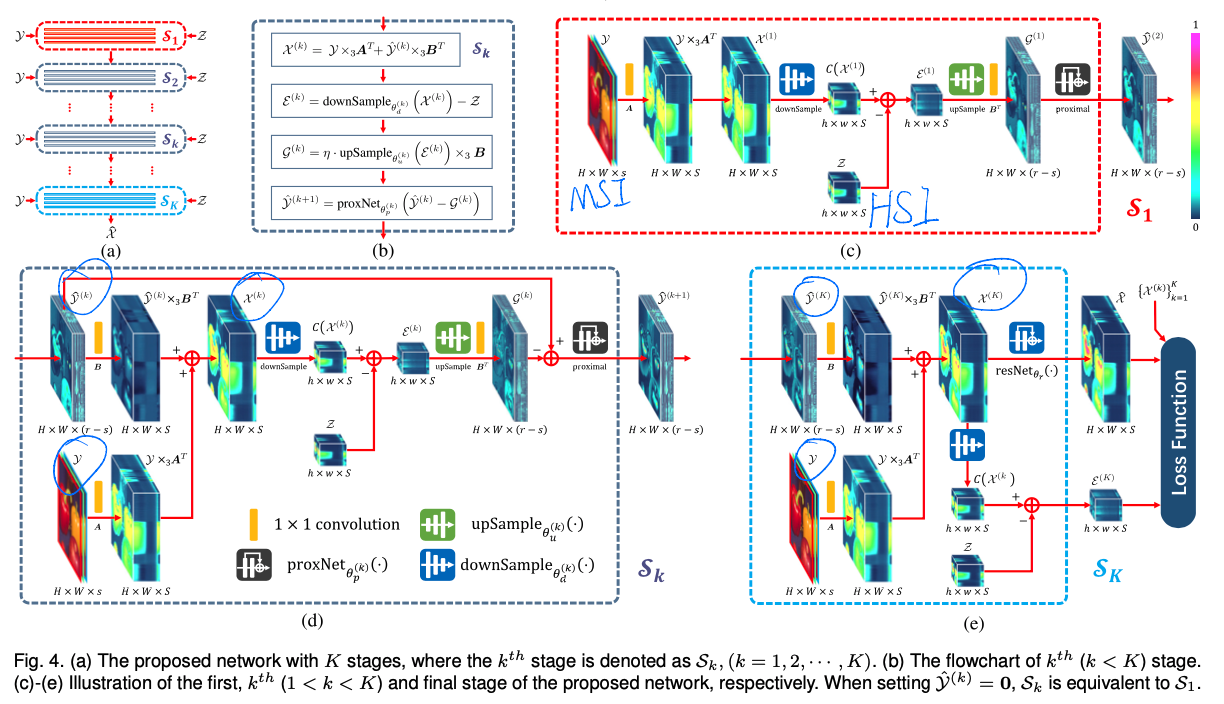
由图(a)可见,这个网络在训练中,一组样本,需要进行k次迭代训练,每次迭代都遵循式(14)的设计。
在训练Loss的设计上,使用最终输出图像$\hat{X}$和GT$X$的L2、每次迭代输出图像$X^{(k)}$和GT$X$的L2以及每次迭代过程中生成的高光谱图像的误差$\varepsilon^{(k)}$这三项之和共同作为Loss。
MSDCNN
[链接] 2018 彩色图像和多光谱图像

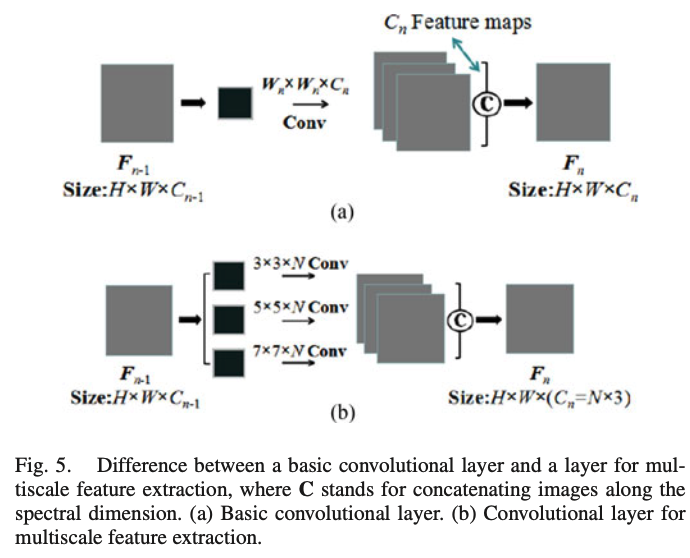 |
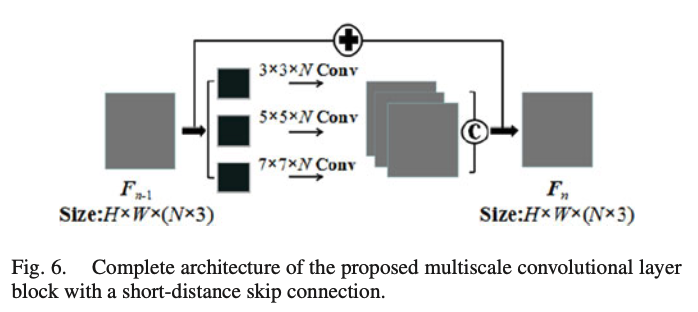 |
|---|
Muti-scale Muti-depth CNN
总体来看,MSDCNN体现了一个多尺度,双分支的设计,并且引入了残差连接。在Deep分支,使用三种不同的卷积核融合图像,
RSIFNN
[链接] 2018 彩色图像&多光谱
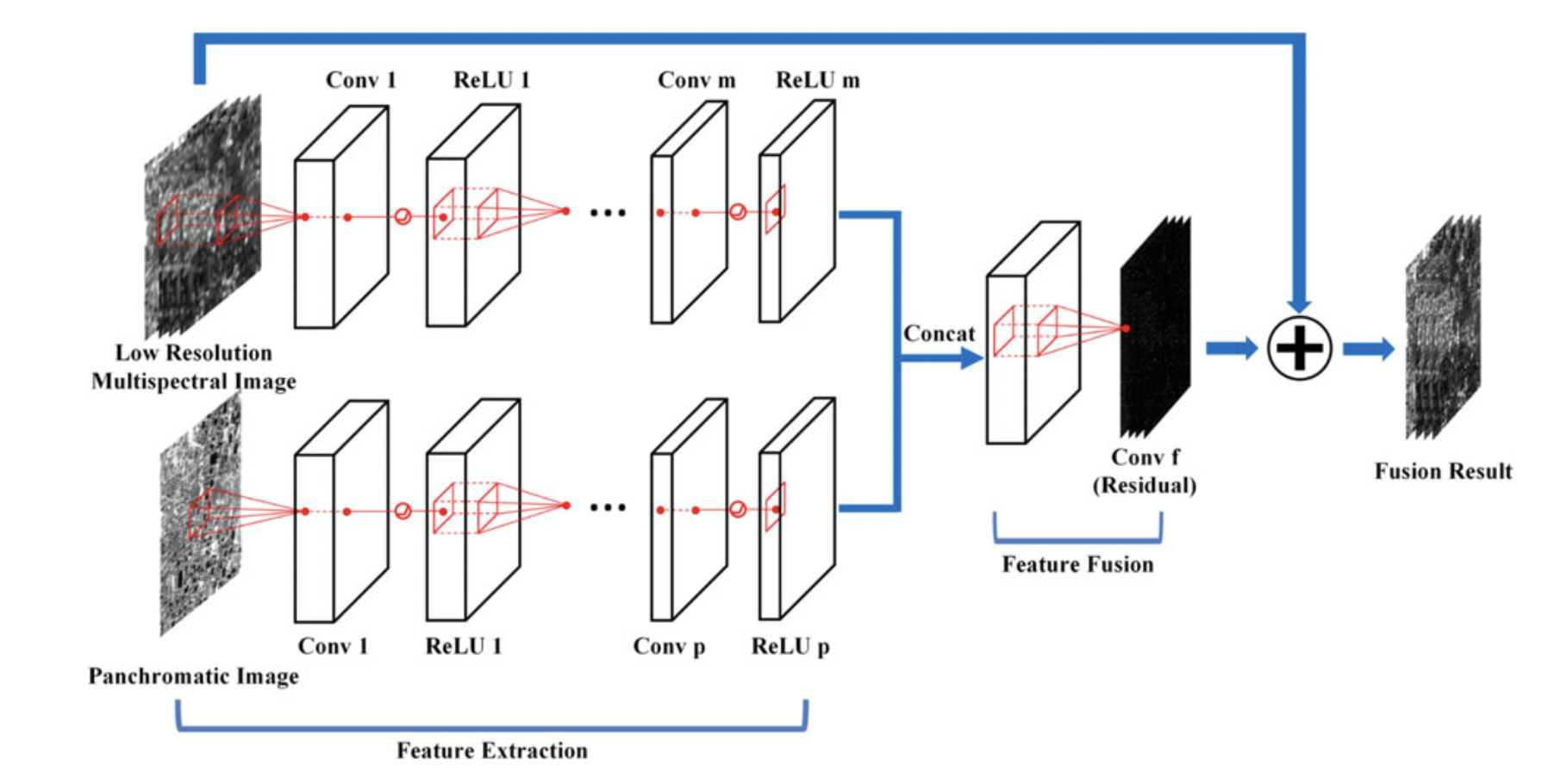
本文是将PAN图像和MSI进行融合。
不同于直接将PAN图像作为MSI的一个通道直接覆盖在其上,然后进行处理的这种做法。本文设计了一个双分支的结构,分别处理PAN和MSI两种图像 。