

Attention is all you need
Motivation
RNN模型固有的输入为序列性质,这阻碍了训练样本并行,当训练样本序列较长时,一个batch的样本量又会受到内存的限制。
Transformer首先应用在机器翻译的任务上,允许更多的并行数据,在模型结构上完全依赖注意力机制。
Self-Attention
参考李宏毅老师的课程,简单地进行总结。
self-attention是一种可以并行处理一组数量不定的向量集的结构,和RNN的输入类似(self-attention结构上是并行,但是RNN是串行的),输入的向量数量并不固定。
如下图输入一组向量$A = \{a^1, a^2, a^3, a^4\}$,对应输出长度相同的一组向量$B = \{b^1, b^2, b^3, b^4\}$。在输出一组向量$B$时,向量$a^1$对应的输出$b^1$是耦合了所有的输入向量的信息得到的,同理B中的每个向量也都耦合了输入的所有信息。
参考这篇笔记[链接],便于理解self-attention的并行化相对于RNN和平行CNN的优势。
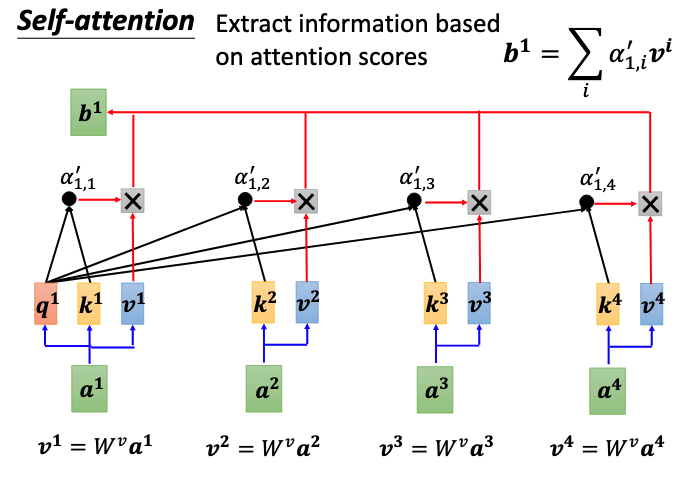
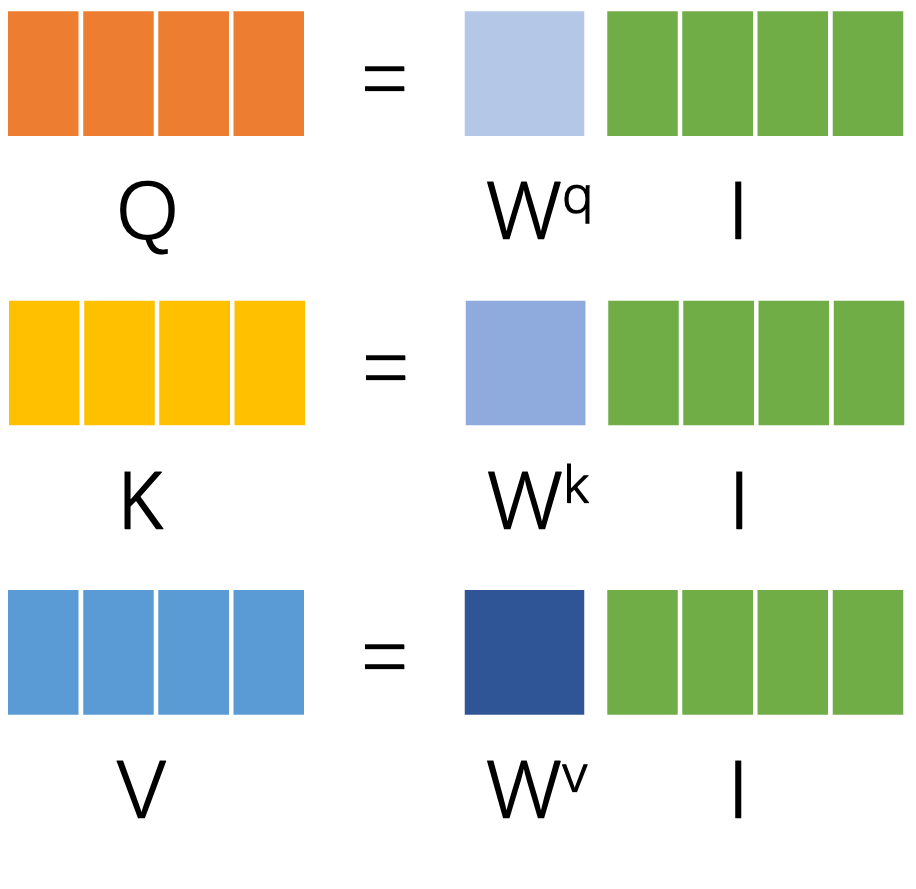
self-attention是如何耦合所有输入的信息,得到输出$b^1$呢?如下图所示,其中 $q^i = W^q a^i,~k^i = W^k a^i,~v^i = W^v a^i$。通过转移矩阵$W^q,~W^k,~W^v$对每个向量$a^i$都可以得到attention机制的三个基本输出query,key和value。在我的另一篇对attention综述的总结中介绍了attention的统一结构[链接],首先是通过合适的Score Function融合key和query的信息得到Energy score,再经过例如Softmax一类的分布函数得到对应value的权重$\alpha$。
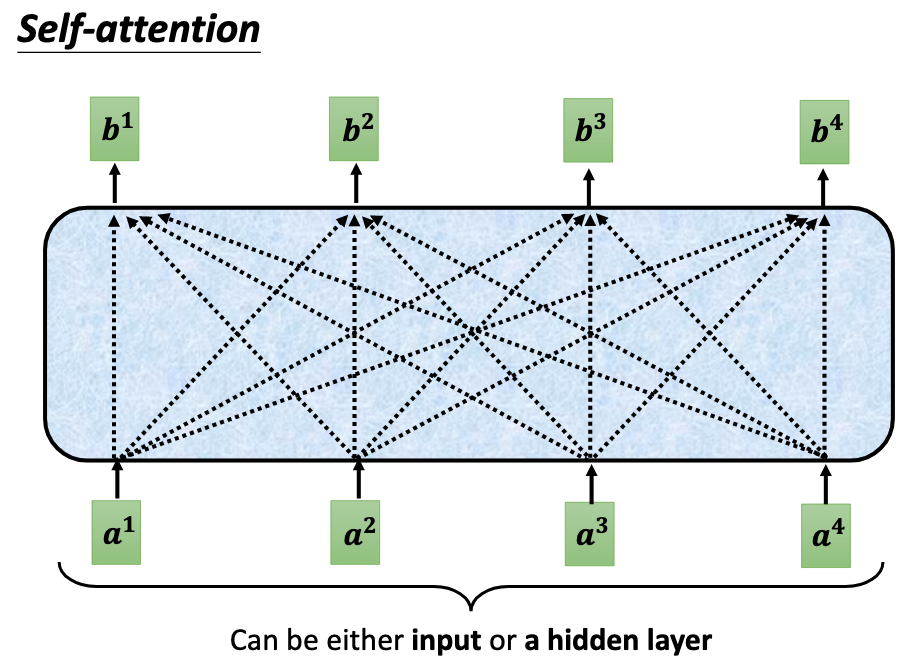
在下图self-attention计算$b^1$结构中,单看最左边的分支,其计算$v^1$对应权重$\alpha_{1,1}^{,}$的方式和上述attetion统一结构的计算过程一样,在计算其他分支的权重$\alpha_{1,i}^{,}$时,则使用的是$q^1$作为query,$k^i,~v^i$作为key和value。最终将每个分支计算出来的值相加便得到了$b^1$。
 |
 |
|---|
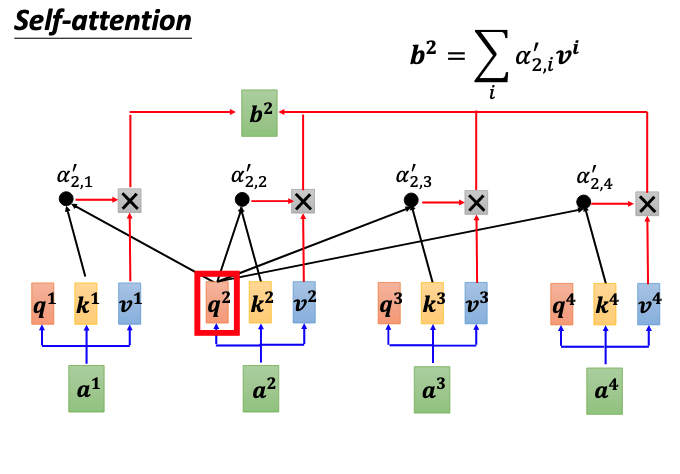
计算$b^2$的过程与计算$b^1$的过程一样,只是使用的query是$q^2$,其他依次类推。
可以看到,使用self-attention的结构,在输入一组向量A,输出一组相同长度的向量B的计算过程中,结构参数仅仅只涉及三个权重矩阵$W^q,~W^k,~W^v$。所以,以这种计算方式,这样的结构能够并行计算任意长度的向量序列,并输出对应长度的向量序列。
Transformer
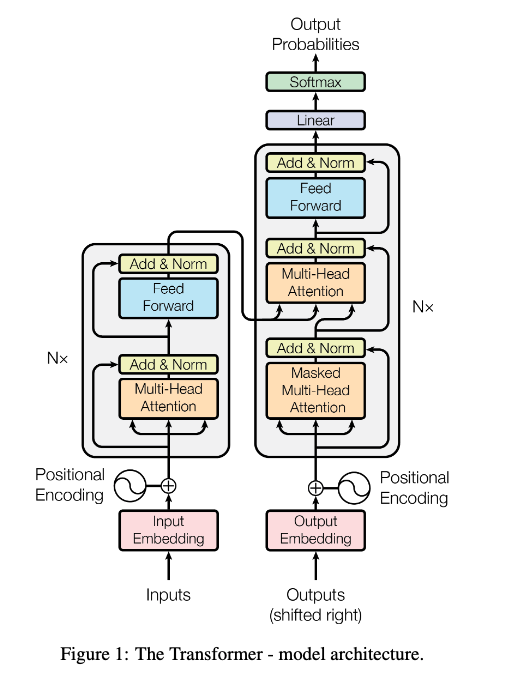
Transformer整体使用encoder+decoder的结构,这种Seq2Seq的模型结构在机器翻译,语音合成等任务中已经比较常见了,其特点在于输出序列的长度不固定,满足这类任务的需求。但是此前encoder或者decoder的结构,使用的是RNN作为基本单元,RNN的模型特点就是在时间维度上串行输入和输出,不能将一组向量序列同时并行输入输出。
 |
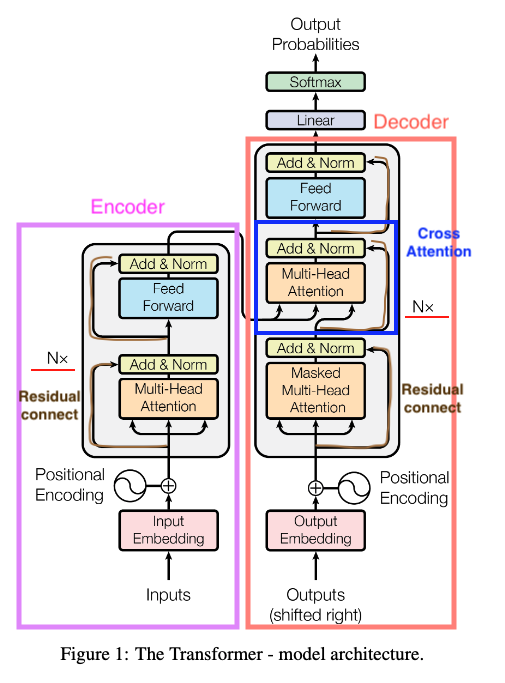 |
Encoder部分由N个紫色block堆叠而成,从下往上进行简单介绍。
- Positional Encoding
在机器翻译任务中,首先要对输入的word做Embedding,也就是将单词映射至向量。再然后对词向量进行位置编码。
进行位置编码的目的是给词向量附加上位置先后的信息。类比RNN,输入的词向量存在时间的先后,但是在Transformer中,由于是并行输入,各个词之间的位置信息需要通过位置编码的形式进行保留。
Transformer中采用的是正余弦位置编码的方式,参考视频进行理解。这是一种相对位置编码的方式。
例如:$pos = 3,~d_{model}=128$,表示单词处于句子中的第3个位置,词向量维度为128,这个单词对应的位置向量则为:
$\{sin(3/10000^{0/128}),~cos(3/10000^{1/128}),~\dots,~cos(3/10000^{127/128})\}$

将位置向量与对应的词向量相加,就得到了位置编码后的结果,就完成了encoder/decoder的输入部分。
正余弦位置编码是如何表示出位置的相对信息的,我理解的并不深刻。正如Paper中所说$PE_{pos + k}$能够用$PE_{pos}$线性表示,我参考视频进行了简单理解:
$\left\{ \begin{aligned}sin(\alpha + \beta) = sin(\alpha)cos(\beta) + cos(\alpha)sin(\beta) \\ cos(\alpha + \beta) = cos(\alpha)cos(\beta) - sin(\alpha)sin(\beta)\end{aligned}\right.$
根据上述公式,可得$PE(pos+k,)$关于$PE(pos,)$的表达式:
$\left\{ \begin{aligned} PE(pos+k,2i)=PE(pos,2i)PE(k,2i+1)+PE(pos,2i+1)PE(k,2i) \\ PE(pos+k, 2i+1)=PE(pos,2i+1)PE(k,2i+1)-PE(pos,2i)PE(k,2i)\end{aligned} \right.$
相对位置确定那么,参数k就确定了,那么两个位置向量间的线性表示就确定了。
Muti-head Self-attention
Muti-head attention只是在one-head的基础上生成了多组query,key和value,其计算方式如下图所示:
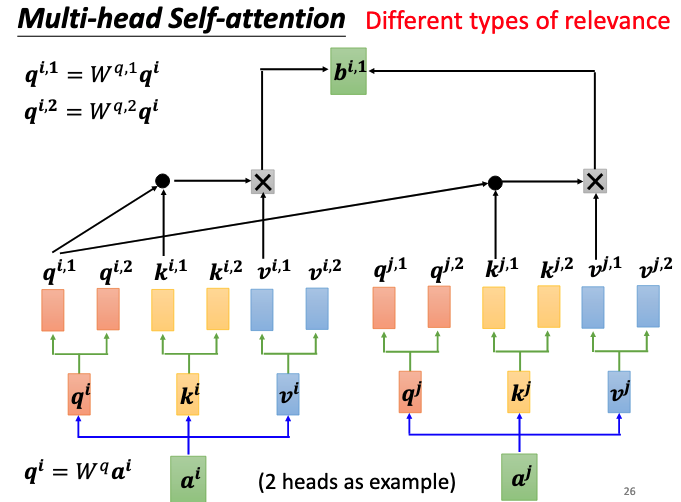
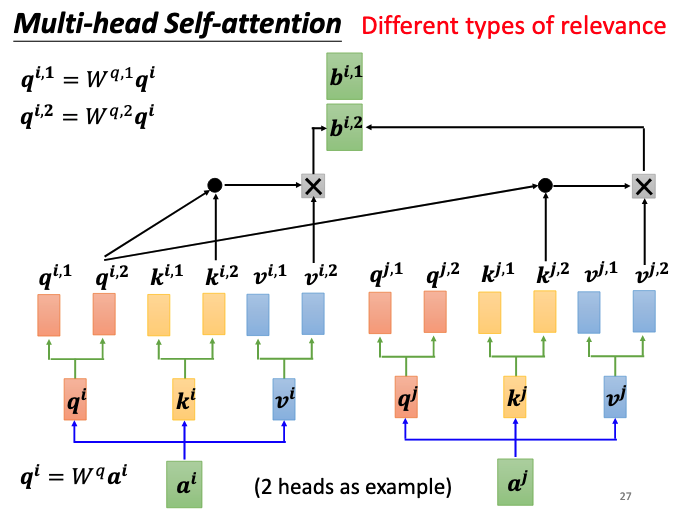
最终输出$b^i = W^o[b^{i,1},b^{i,2}]$,将多组query,key和value计算的输出进行拼接,再乘上输出矩阵就可以得到最终的输出。
- Add & Norm
Add这里指的就是残差连接,对于输入的词向量$x$,经过Muti-head attention后得到对应输出$H(x)$,再相加得到$x’=x+H(x)$。残差连接,使得模型可以堆叠得更深,因为它缓解了深层网络训练过程中的梯度消失问题。
Norm这里指的是Layer Norm,并不是Batch Norm。LayerNorm是对同一个样本中的所有词向量做Norm。
BatchNorm在CV中应用比较广泛,就是在样本维度上对每个样本的某一个通道做Norm,而LayerNorm放在CV中则理解为在通道维度上对一个样本做Norm。
举个例子来说,一个batch中有N个样本,每个样本$i$中有$C_i$个词向量,BN就是求取出每个样本的第j个词向量,然后做Norm。LayerNorm就是取出第N个样本的所有词向量做Norm,他们做Norm的维度是不一样的。
我说的有点绕,不如去看看图。
- FeedForward
FeedForward就是一个的基本的前馈神经网络(全连接层)。
以上各个模块堆叠就构成了一个基本的encoder block,再通过这样的encoder block的N层堆叠,就构成了Transformer的encoder结构。
Decoder部分由右边橙色的部分堆叠而成。
- Cross attention
首先介绍橙色部分中间蓝色框框与encoder相连的部分。这里也是一个Muti-head Attention模块,但是它的输入同时来自encoder和decoder。其中encoder的输出提供key和value,decoder则提供query,这与attention在由RNN组成的Seq2Seq模型中的使用是一样的。
见上一篇博客[链接],在由RNN组成的Seq2Seq模型中应用attention机制中,将上一时刻decoder的状态向量$s_{t-1}$作为query,而之前时刻encoder的隐层输出$h_j$作为key和value。
在Transformer的cross-attention部分也是如此,将decoder中前Masked-attention层的输出作为query,将encoder的输出经过变换作为key和value,来共同求得corss-attention的输出$v$。
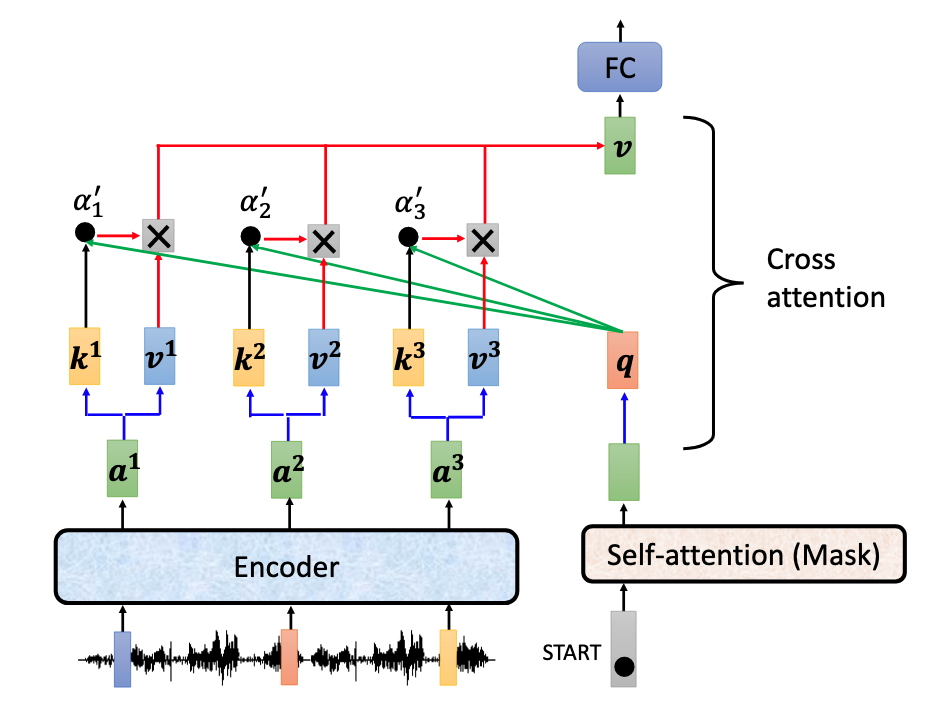 |
 |
这一个block在后面同样也使用了add&norm层,这里就不过多赘述了。
- Masked attention
decoder的输入输出,要区分训练还是推理。
首先我们知道,基于RNN的decoder是时间驱动的,一句话中的各个词向量是逐时刻输入的。只有当t时刻的decoder输出了,才能得到t+1时刻decoder的输入。
训练
由于transformer可以并行输入,那么在并行输入时如何让decoder不一次性看完所有GT呢?
在训练时,decoder直接输入一组GT的词向量,经过位置编码后送入Masked muti-head self-attention。
其中Mask在attention中的具体操作如下图,也就是在计算完score map后要加上一个mask矩阵,其他操作都一样。
 |
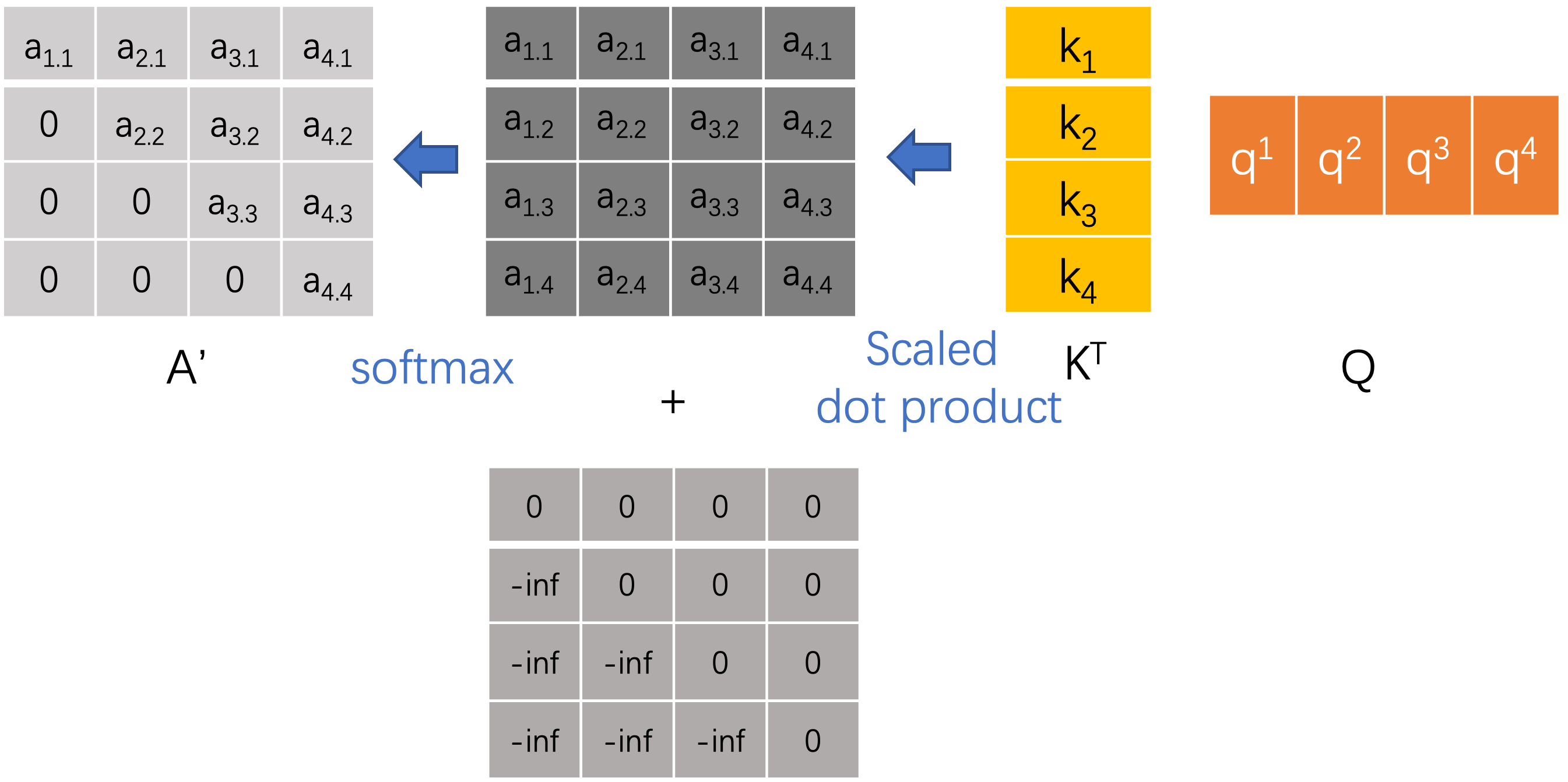 |
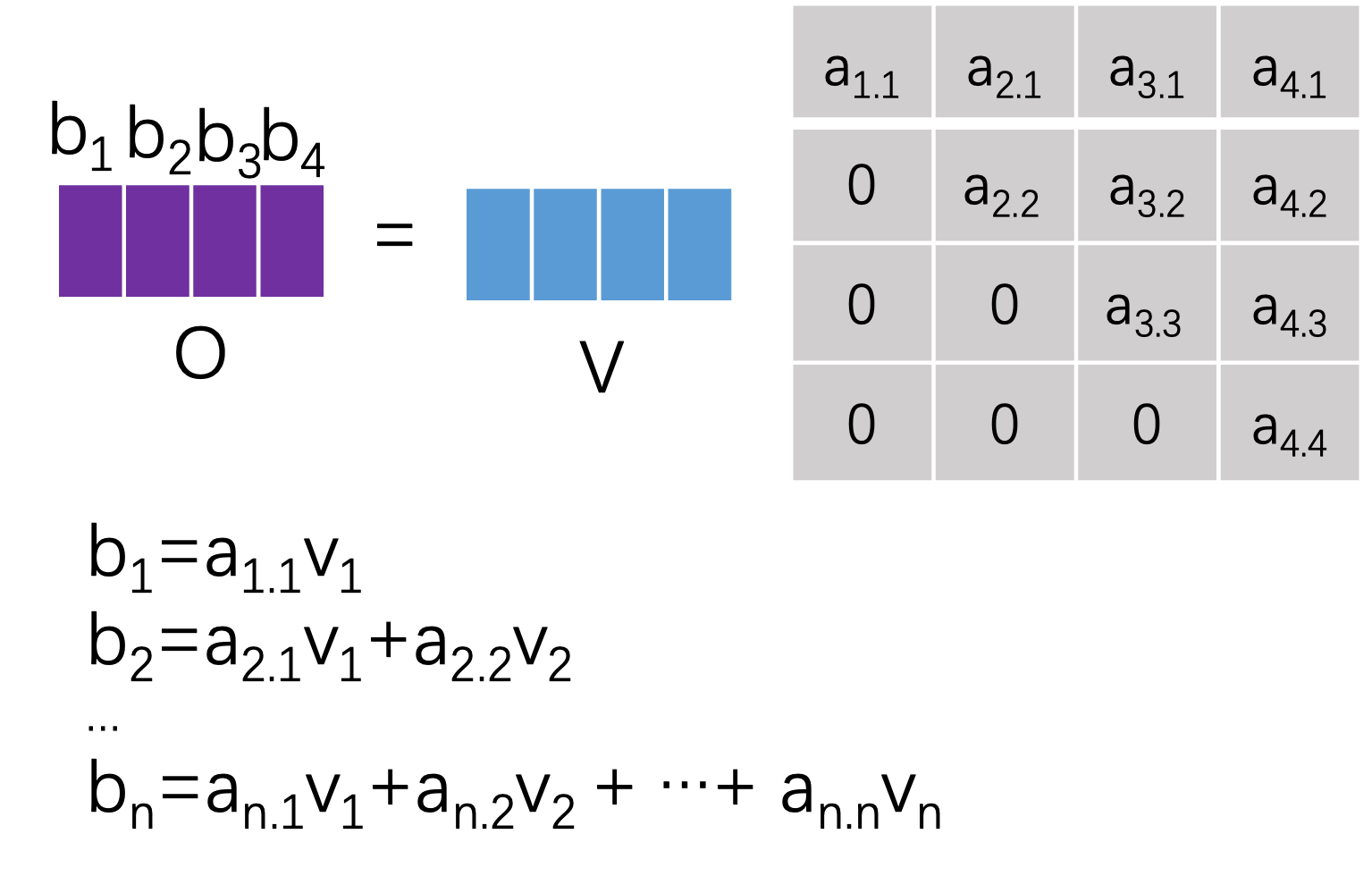
可以看到$\{i_1, i_2, i_3, i_4\}$对应的输出$\{b_1, b_2, b_3, b_4\}$,$b_1$仅仅利用了$v_1$的信息,$b_2$仅仅利用了$v_1, v_2$的信息。这样就利用mask操作完成了。Mask主要目的在于训练时,使得decoder不能利用未来的信息。
推理
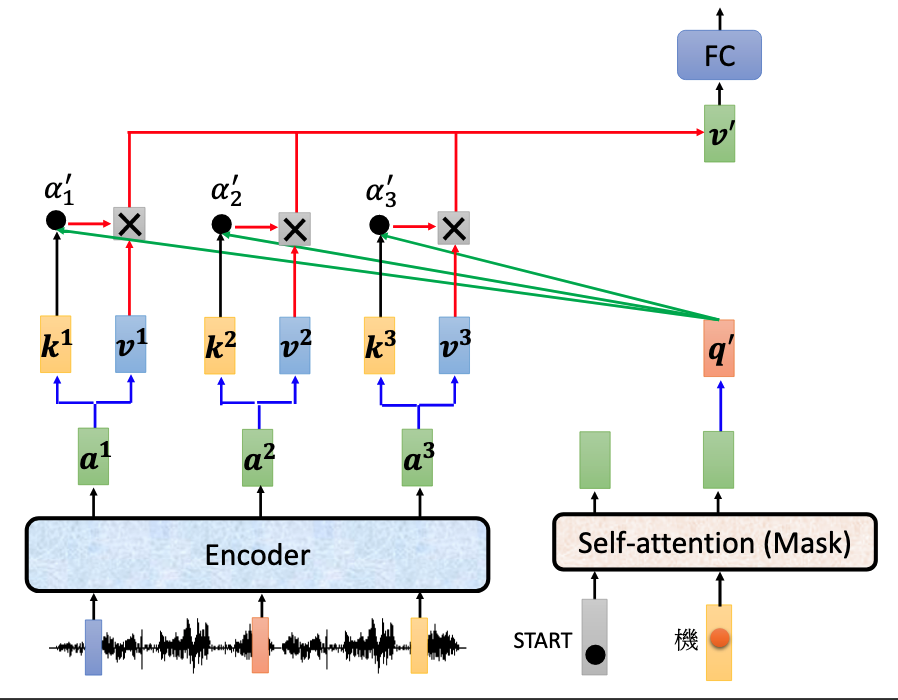
在执行推理时decoder实际上和RNN类似,decoder端开始时只会输入一个开始信号start-token,然后使用start-token经过decoder产生的输出$o_1$(也就是对第一个单词的翻译的结果)补充到decoder端输的入,将$\{start-token, o_1\}$作为decoder的第二次输入,这样依次补充,直到decoder输出end信号。
以上是我关于Transformer结构中难懂的点的理解,如果有错误,欢迎批评指正。关于其训练过程,以及更细节的问题,我还没有深究。