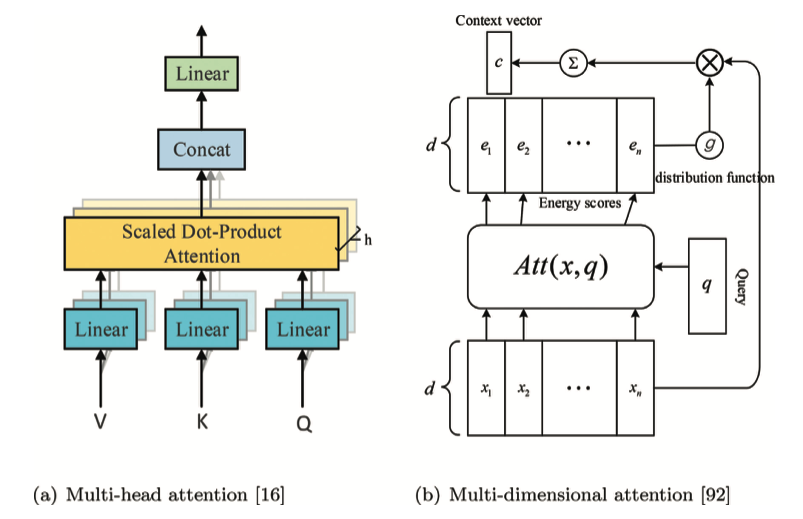
A review on the attention mechanism of deep learning
读完这篇综述,对attention有了一些简单的了解,这里对内容和值得引文的文章进行了简单的总结。
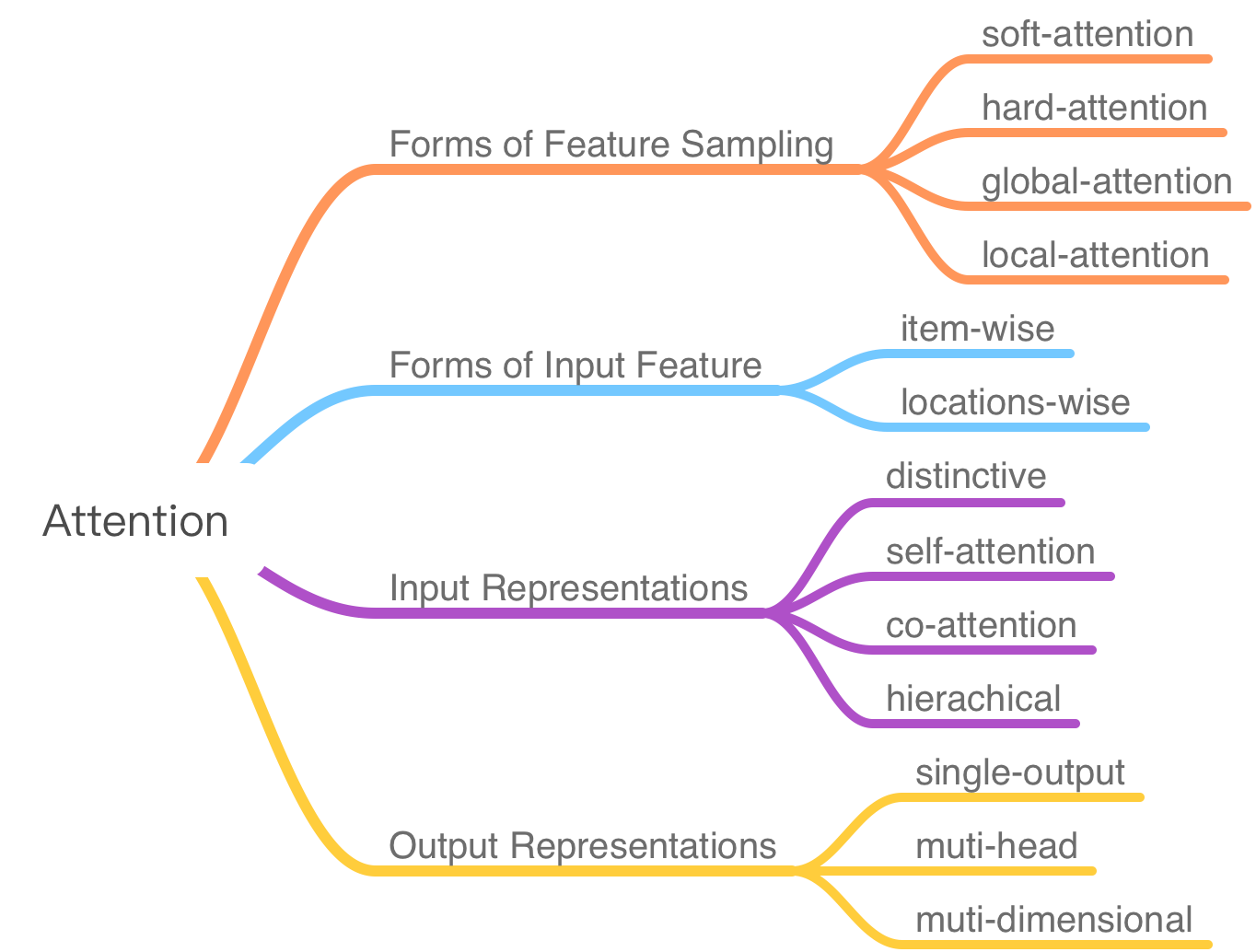
attention机制是一个开支散叶非常多的领域,对其进行分类讨论非常的有必要。首先从人本身的注意利形式开始:
- Bottom-up:可以理解为潜在的注意力,例如:在嘈杂的对话声中,人们往往更可能听到声音最大的那一种,这种形式在DL中与max-pooling以及gating machanism较为相似。
- Top-down:可以理解为聚焦的注意力,例如:人们主积极动地关注某一个类物体,这种形式往往在DL的特定任务任务中使用。
而如果根据attention模型结构上的区别,主要可以划分为以下几类:
在分类总结各种不同结构的模型前,可以先看看attention模型的统一结构
1. attention的统一结构
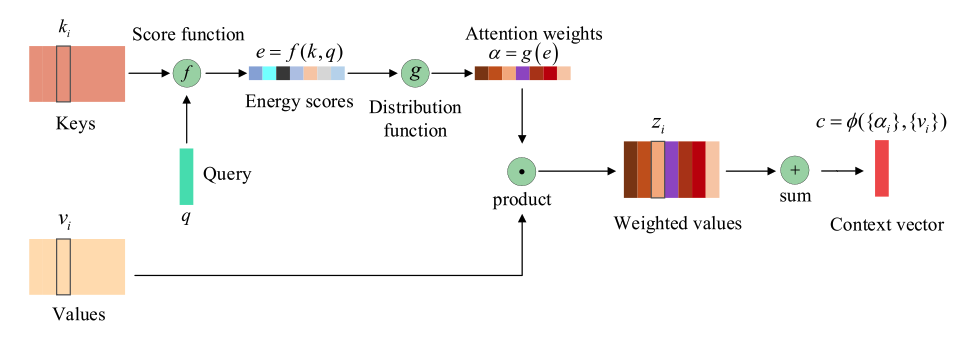
Vaswani对attention有一个非常好的总结:attention机制是一种将query和Key-Value对映射至输出的结构,该结构通过组合key和对应的query计算出每一个value对应的权重,然后将value的加权和作为输出。
the atten- tion mechanism ‘‘can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is com- puted by a compatibility function of the query with the corre- sponding key。
attention可以分为两步,第一步是根据keys和query计算attention权重,对应于上图上方的分支,第二步则根据values和对应的weigth计算出context vector。
以Neural machine translation by jointly learning to align and translate为例,作者首次提出了attention,并将其应用至翻译任务中,其中attention是作为Seq2Seq模型的一部分,其中Key和Value相同,是各个时刻状态下encoder的输出$h_j$,query是decoder上一时刻的状态向量$s_{i-1}$,然后计算出权重$\alpha$。
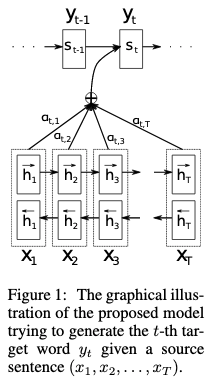
其中decoder的状态向量$s_i = f(s_{i-1}, y_{i-1}, c_i)$,(需要熟悉Seq2Seq),下面则是本文中使用的attention表达式:
其中contex vector $c_i = \sum\limits_{j=1}^{T_x} \alpha_{ij}h_j$
其中权重$\alpha_{ij} = \frac{exp(e_{ij})}{\sum^{Tx}_{k=1}exp(e_{ik})}$ ,Score function为$e_{ij} = a(s_{i-1}, h_j)$
在attention中整合Keys和Query计算出Energy score的Score function方法有很多,在不同场景下各有优势:

2. Forms of Feature Sampling
Soft-attention
Neural machine translation by jointly learning to align and translate中使用的就是soft-attention,在计算contex vector时,使用的是values加权平均的方式,这样整个attention模块相对于输入是可微的(因为仅仅只涉及Key,Value, Query的四则运算),可以通过反向传播的方法进行训练。
Hard-attention
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention在看图说话的任务上应用了attention,称之为hard-attention。因为还没有读过这篇文章,结合一篇知乎上的专栏谈谈我的理解,专栏中以Recurrent Models of Visual Attention为例。
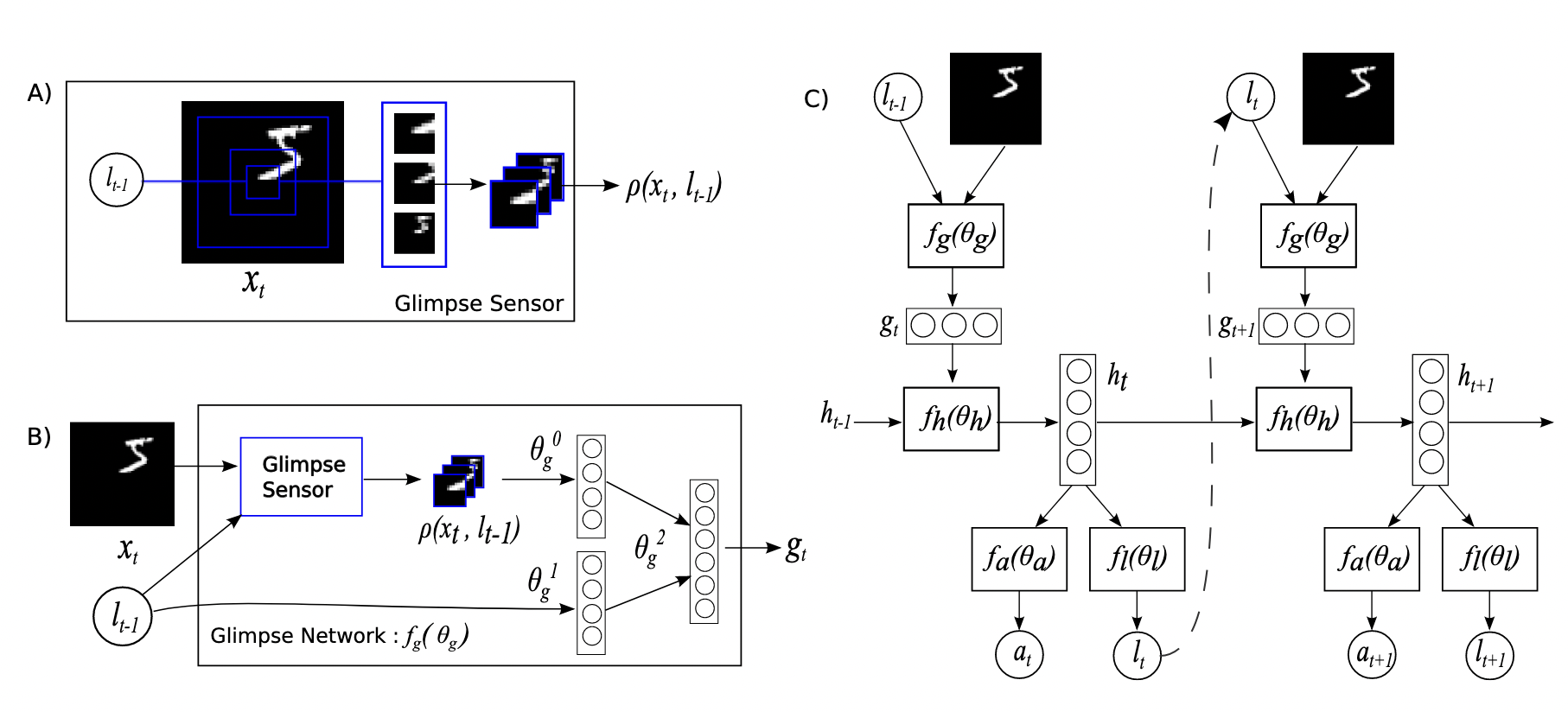
图 B)结构显示了图片局部区域的学习,其输入为采集的整个场景图像的局部信息和第$l_{t-1}$的RNN隐藏层向量,$l_{t-1}$指导着Agent下一时刻的行动。Agent的局部信息采集的结构见图 A)部分,主要有某一点为中心的三个局部区域大小的图像采集,而不是采集整张图像。
Agent通过强化学习在每一个时刻做出决策,选取完整图像的局部信息,这个寻找图像前景局部区域的过程,可以视为Hard Attention的过程。
总之,Soft-attention通过计算权重来求Values的加权和,而Hard-attention通过强化学习的决策过程(可以视作一种离散分布)来求Values的组合。
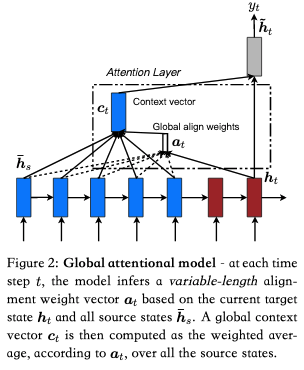
Global-attention/Local-attention
Effective approaches to attention-based neural machine translation在机器翻译上提出了global-attention和local-attention。
global-attention和soft-attention的整体思想一样,但在两篇文章中也存在一些差异。
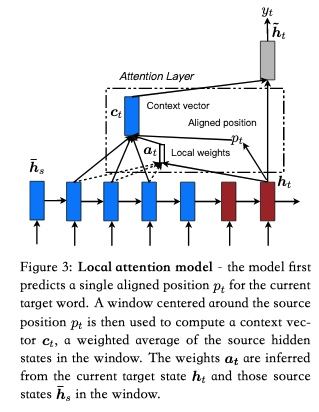
local-attention则如其名,并不是对所有的Values都加权求和,在该文章中,作者设计了一个窗口,仅仅关注窗口中的隐藏层向量。
 |
 |
3. Forms of Input Feature
Item-wise
Item-wise要求输入的是逐项的序列,例如:
- Neural machine translation by jointly learning to align and translate,Key和Value是一个时间序列,每一项对应encoder的隐层状态。
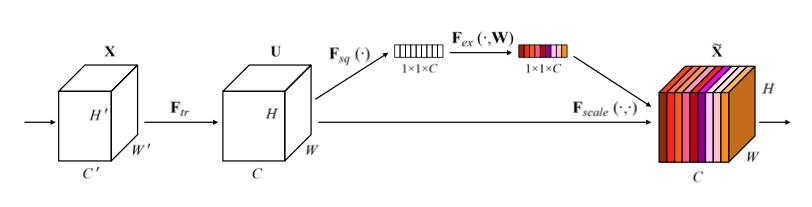
- Squeeze-and-Excitation Networks,Key和Value是逐通道的,每一项对应一个通道。
Location-wise
location-wise attention针对的是难以获得不同输入项的任务,通常这种注意力机制用于视觉任务。
- Recurrent Models of Visual Attention中的Value是特征图某一个局部块。
- Multiple object recognition with visual attention,没有详细了解,不过看样子和上一篇差不多。
4. Input Representation
distinctive attention
大多数attention模型都包涵两个特征:
- 模型包括一个单一的输入和相应的输出序列。
- Keys和Queries是独立的序列。
这样的attention模型也可称之为distinctive attention,An Attentive Survey of Attention Models。
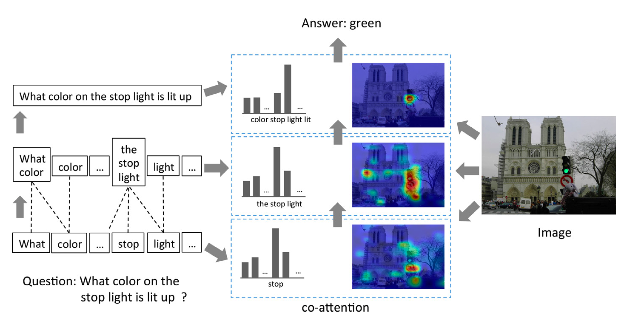
co-attention
Hierarchical question-image co-attention for visual question answering提出的多输入的attention模型
Muti-grained(coarse-grained/fine-grained)
Multi-grained attention network for aspect-level sentiment classification
Self-attention
Inner attention based recurrent neural networks for answer selection
Self-attention中key,query,value是同一个序列的不同表示,这样的结构被使用在了Tranformer中。
hierachical attention
Hierarchical attention networks for document classification
5. Output Representation
Muti-head
Muti-dimensional
DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding