

据本文提及,这是第一份利用CNN来对高光谱图像进行分类的工作,作者在LeNet-5的基础上,对其进行结构调整使之适合HSI的分类任务。
相关工作
在此之前,作者提到的HSI的相关工作主要有以下部分,主要提及的还是CNN在图像处理领域的进展,感觉这个时段DL的方法确实还并未迁移至HSI上。
- SVM:
- “Spectral–Spatial Classification of Hyperspectral Imagery Based on Partitional Clustering Techniques,” in IEEE Transactions on Geoscience and Remote Sensing, 2009
- Support vector machines in remote sensing: A review. 2011
- Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network. in IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. 2015
- Semi-supervised:
- SAEs:
模型介绍
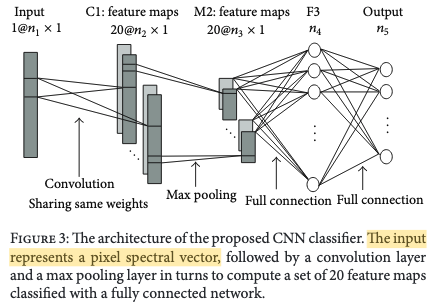
模型的输入为某一个像素的谱向量长度为$n_1$,经过$20 \times k_1 \times 1$的卷积核,得到C1层的特征图,尺寸为$20 \times n_2 \times 1$。
其中$n_2 = (n_1 - k_1)/1 + 1$。
从C1至M2是最大池化操作,池化核为$k_2 \times 1$,得到的M2的特征图尺寸为$20 \times n_3 \times 1$。
其中$n_3 = n_2/k_2$。
然后是一层全连接层F3,并再接一层全连接作为输出。
任务为多分类任务,作者使用的损失函数为交叉熵损 $J(\theta) = -\frac{1}{m} \sum \limits_{i=1}^{m} \sum \limits_{j=1}^{n_5} 1\{j=Y^{(i)}\}\log{(y_j^{(i)})}$。
实验
作者实验主要在 Indian Pines 、Salinas、University of Pavia这三个数据集上进行了实验。
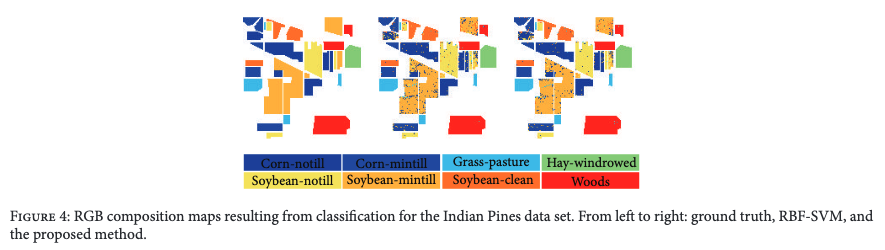
从可视化的结果上来说,分类效果相较SVM并不明显。不过给我感觉到,HSI图像的分类是逐像素进行分类的,区别于我们常规的图像分类。个人认为常规的图像分类是主要是根据整张图像的语义信息进行分类,但是HSI图像的分类任务是在一个像素上进行的,仅仅需要对一个谱向量进行分类。
作者在文中也有提到,本模型的结构和在语音识别中应用CNN处理频域信号的模型有相似之处,因为处理的数据都是一维的。
 |
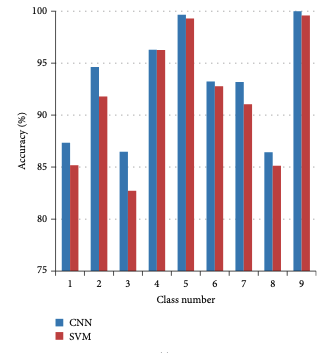 |
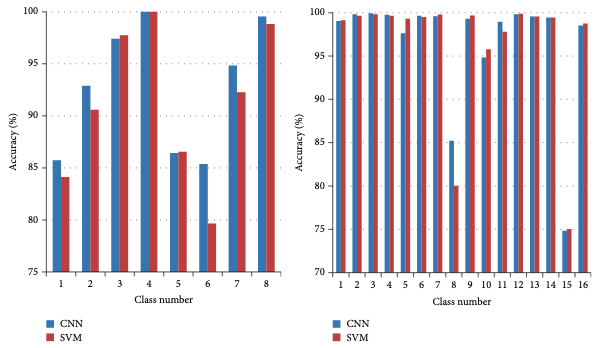
在三个不同的数据集下CNN的方法在准确率上也有一定的优势。
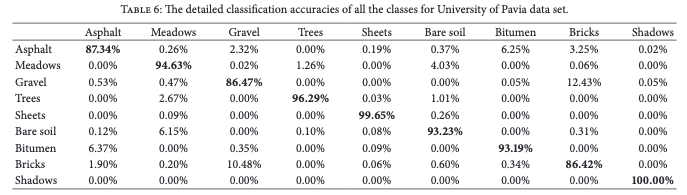
相较于以上实验,我认为更具价值的实验是这个,作者统计了每类对象的识别情况,每行代表其标签,每列代表网络分类的结果。
并且,作者对Pavia数据集中每类的谱特征(103通道)进行了绘制,即将1维长度为103的向量,绘制成平面中的曲线。可以观察到每种类型对应的谱向量分布都各有特征。
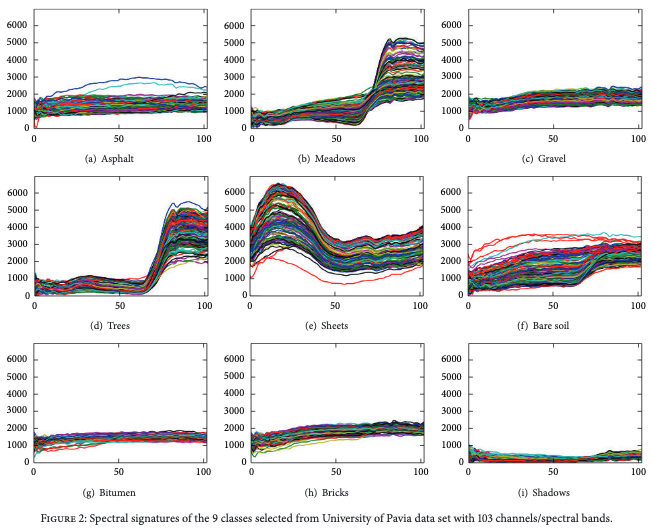
综合谱分布的可视图和网络分类情况的表格,可以直观地感受到特征区分度相对大的Shadows、sheets类,其分类成功率较高。这也能直观地感受到CNN有效地学习到了谱分布。
总结与展望
- Siamese Network可能有效,作者认为Siamese Network在小样本情况下仍然能够保持较好的鲁棒性
- 无监督学习
- 不单纯利用谱特征,而是空间特征与谱特征相结合